Recipify
Recipify - A social recipe-sharing platform where food lovers discover, create, and share culinary creations.

1. Project Overview & Goal
The Problem
Home cooks and food enthusiasts struggle to organize their recipes in one place. Existing recipe apps lack social features, making it hard to discover new dishes from friends and the cooking community.
Traditional recipe websites are cluttered with ads and SEO-optimized stories. Users want a clean, fast, mobile-first experience focused on cooking—not endless scrolling.
The Goal / My Solution
Recipify is a social recipe-sharing platform where users can create, save, and discover recipes. Built with Next.js for optimal performance and AWS serverless architecture for scalability.
2. Tech Stack
Frontend
Backend
Database
Cloud & Infrastructure
DevOps & Tools
3. Architecture & System Design
Version 1: Current Implementation
My implementation for this project was a v1 'Monolithic Proxy' design. It was built for rapid development, low cost, and speed of shipping. The architecture is simple, with an API Gateway forwarding all requests to a single 'monolithic' Lambda that runs my entire Fastify API.
When a user uploads a recipe image, the flow is: Frontend → API Gateway → Lambda (image processing with Sharp) → S3 bucket → CloudFront CDN.
This v1 design is effective, but it presents three major bottlenecks that prevent it from scaling to a production-grade, high-traffic application. The v2 'Scalable Solution' is my design for a true, enterprise-grade system that directly solves these three bottlenecks
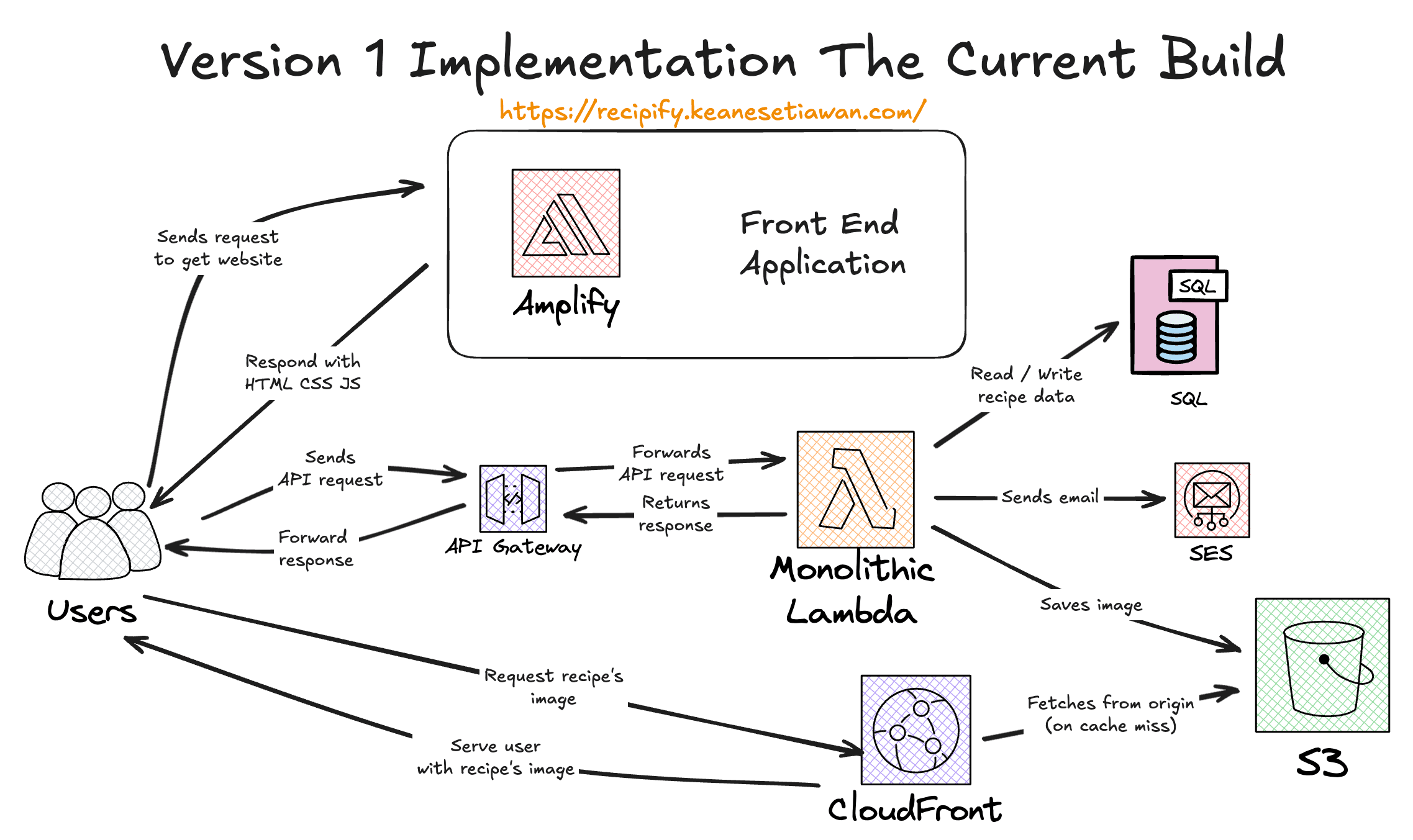
Recipify v1 Architecture - 'Monolithic Lambda' (As built)
Bottlenecks
Monolithic Lambda acting as an entire API server
A single Lambda function handles all routes (auth, recipes, uploads). This violates the single-responsibility principle and makes it harder to scale individual features independently.
Image uploading and processing directly on API server
Images are sent through API Gateway to Lambda for processing, which blocks the API response and limits uploads to 6MB due to Lambda payload constraints. Users must wait for compression before seeing success.
No cache layer between user and database
Every recipe fetch hits the database directly, increasing query load and latency. Frequently accessed recipes should be cached in a caching layer like ElastiCache or Redis.
Version 2: Scalable Asynchronous Architecture
The v2 design solves all v1 bottlenecks and it is a resilient, high-performance, and scalable system designed to handle millions of users.
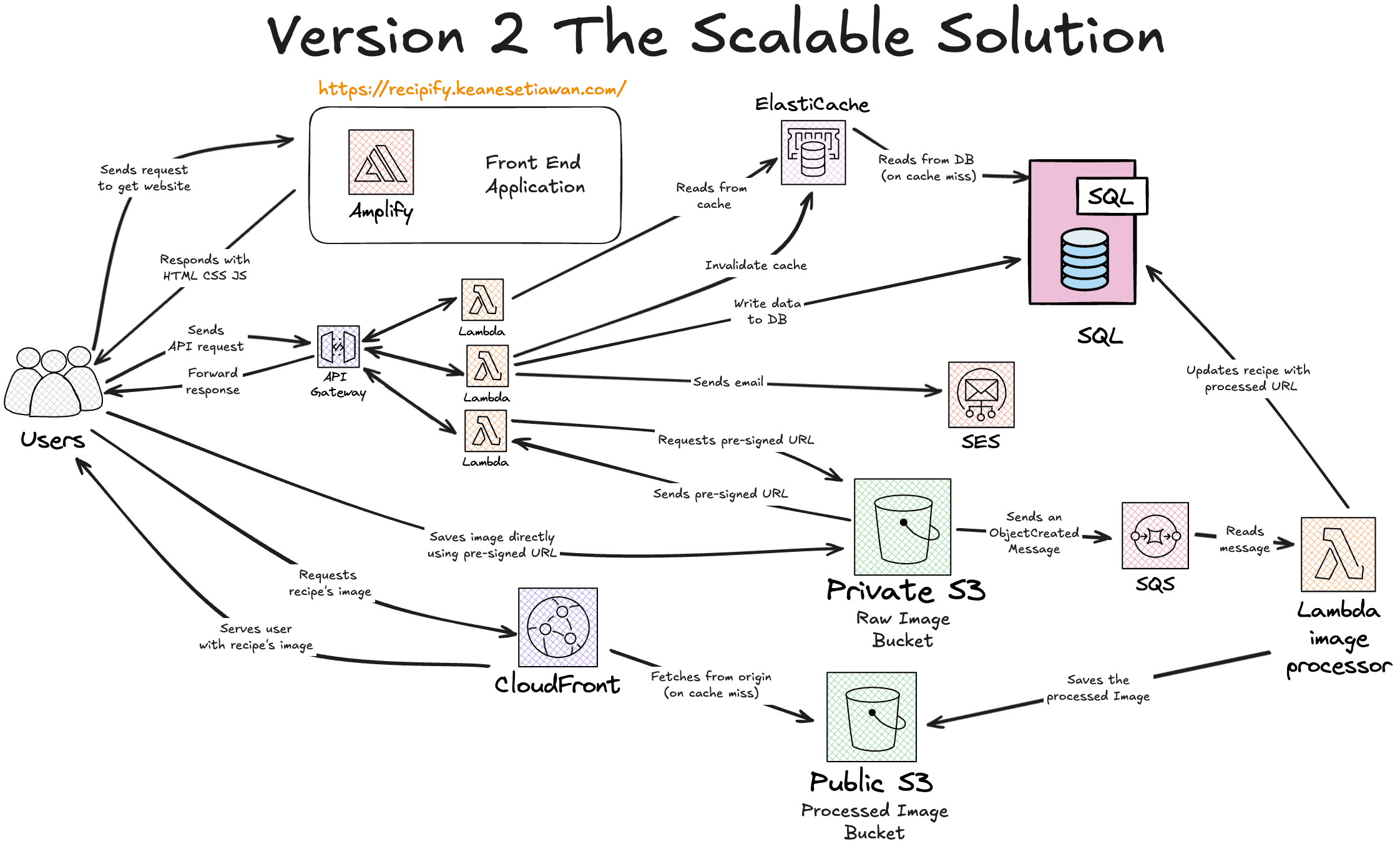
Recipify v2 Architecture - 'Scalable Solution' (Event Driven Architecture)
4 Key Evolutions
API Architecture: Monolithic Lambda → Distributed Microservices
v1 Problem: The entire Fastify API runs in one monolithic Lambda. This causes slow cold starts (the whole 50MB+ app must boot), poor security (the one Lambda needs all permissions), and inefficient scaling (a spike in GET requests scales the entire monolith).
v2 Solution: I refactored the API into a microservice pattern. The routing logic moves from Fastify to API Gateway. Each endpoint (e.g., POST /recipes) now routes to its own small, single-purpose Lambda.
Business Value: This provides dramatically faster cold starts, granular security (each Lambda only gets the one permission it needs), and efficient scaling (we only pay to scale the 'hot' endpoints).
Image Uploads: In-Memory Proxy → Pre-signed URLs
v1 Problem: The user uploads an image to the Lambda, which holds it in memory. This is slow for the user and, more critically, fails for any file larger than the 6MB Lambda payload limit.
v2 Solution: The Lambda never touches the file. The client requests a secure, temporary pre-signed URL from the API. The client then uses this URL to upload the file directly to a private S3 bucket.
Business Value: This is infinitely scalable bypasses the 6MB limit, and provides a blazing-fast UI response, as the user is no longer blocked by our server.
Image Processing: Synchronous → Asynchronous with SQS
v1 Problem: The sharp image processing happens synchronously inside the API request. If the processing fails, the user's entire upload fails.
v2 Solution: The v2 pre-signed URL flow is paired with an asynchronous 'worker' process. When the new image hits the private S3 bucket, S3 sends an ObjectCreated message to an SQS Queue. A separate 'Image Processor' Lambda polls this queue, safely processes the image in the background, and saves it to a public S3 bucket.
Business Value: This is 100% resilient. The SQS queue acts as a 'shock absorber' that can handle 10,000 simultaneous uploads, and if a processing job fails, it's automatically retried without the user ever knowing. No upload is ever lost.
Database Reads: Direct Query → L2 Cache Layer
v1 Problem: Every single API request for a recipe (GET /recipes/123) results in a 'hit' on our SQL database. This is expensive and slow under high traffic.
v2 Solution: I've added an in-memory cache layer like ElastiCache. The API now uses a 'cache-aside' pattern:
Read: The API server checks ElastiCache first. If the recipe is there (a 'cache hit'), it's returned instantly. Cache Miss: If not, the API queries the SQL Database, saves a copy to ElastiCache for next time, and then returns the data.
Write: When a recipe is updated, the API updates the SQL Database and then sends a DELETE command to the cache to invalidate the old data.
Business Value: This provides sub-millisecond latency for all popular recipes, dramatically reduces database costs, and protects the database from read-heavy traffic spikes.
4. Implementation Decisions & Trade-Offs
I chose Fastify over Express for the backend API to achieve 30% better throughput performance, which is critical when serving recipe images and handling multiple concurrent users. The trade-off is a smaller community and fewer plugins compared to Express.
For the database, I used Supabase (PostgreSQL) with Prisma ORM instead of MongoDB because recipe data has clear relationships (users → recipes → ingredients). SQL's ACID guarantees ensure data consistency for user accounts and recipe ownership.
Image uploads use AWS S3 and a CloudFront CDN for global performance. The v1 implementation processes images synchronously via a Lambda proxy, a trade-off that was significantly faster for initial development but limits file uploads to 6MB. The planned v2 architecture solves this by using S3 pre-signed URLs for direct client uploads and an asynchronous Lambda worker for processing, removing all size limits and improving the user experience.
5. Key Features
Full Recipe & Content Management
This is the core of the application, providing authenticated users with full, secure CRUD (Create, Read, Update, Delete) control over their own content. The 'Create' and 'Update' flows are fully integrated with the asynchronous image upload architecture. When a user saves a recipe, the text metadata is written to the SQL database, while the image is simultaneously uploaded via the pre-signed URL to S3, ensuring a fast, non-blocking user experience.
Secure Email Verification & User Onboarding
To ensure data integrity and prevent spam sign-ups, I implemented a token-based email verification system. When a new user registers, the API server generates a unique, short-lived, and signed JWT (JSON Web Token). This token is then sent to the user's email via AWS SES (Simple Email Service). A dedicated backend endpoint validates this token, activating the user's account in the database and confirming they are the true owner of the email address.
Robust Authentication & Session Management
The application's security is built on a modern JWT-based authentication flow. Upon successful login, the API server generates a signed JWT (containing the user ID and role) and sends it to the client in a secure, httpOnly cookie. For every subsequent request to a protected endpoint, the API Gateway and Lambda backend validate this token's signature to authenticate and authorize the user, ensuring they can only access or modify their own data.
6. Challenges & Lessons Learned
High-Latency, High-Cost Image Serving
Challenge:
My application's images were loading very slowly (especially for international users) and my AWS data transfer costs were high. I was serving images directly from their S3 object URL (e.g., s3.us-east-1.amazonaws.com/...). This meant every user, no matter where they were, had to fetch the image from a single server in one location. This was slow and I was paying S3 'data egress' fees for every single request.
Solution:
I researched and implemented AWS CloudFront, a Content Delivery Network (CDN). I configured the CDN to use my S3 bucket as its 'origin,' and then updated my application to serve all images from the new CloudFront URL.
Lesson Learned:
This was a massive 'aha' moment. I learned that a CDN is not just a 'nice-to-have' but an essential part of a scalable application. It solved both problems at once: image latency dropped from ~2-3 seconds to under 300ms by caching images at 'edge' locations, and my S3 data transfer costs were dramatically reduced.
Inconsistent API Performance (Lambda Cold Starts)
Challenge:
My API response times were inconsistent, with some requests taking over 1.5 seconds while others were 50ms. After investigating, I identified the classic 'Lambda cold start' problem. My v1 'monolithic' Lambda, which ran my entire Fastify API, had to boot up its whole 50MB+ container before it could process a request.
Solution:
As a short-term v1 fix, I used the Serverless WarmUp plugin to automate the process of keeping my lambda warm. However, the real solution I designed (as part of my v2 architecture) is to refactor this monolith into single-purpose 'microservice' Lambdas.
Lesson Learned:
I learned the real-world trade-offs of the 'monolithic Lambda' pattern. It's fast to develop but scales poorly. This experience proved why microservice architectures are so critical for performance. A small, 500KB 'getRecipe' Lambda has a negligible cold start compared to a 50MB monolith.
The Complexity of Full-Stack Ownership
Challenge:
This was the first project where I was solely responsible for the entire system, from ideation to deployment. I quickly learned that 'full-stack' means more than just FrontEnd and BackEnd. The biggest hurdle was becoming my own DevOps and Cloud Engineer. Configuring AWS was a steep learning curve, especially creating secure IAM policies and networking rules to ensure my services (Lambda, S3, RDS) could only talk to each other and nothing else.
Solution:
I adopted an 'Infrastructure as Code' (IaC) mindset. I used the serverless.com framework to define all my AWS resources, permissions, and environments in a single serverless.yml file. This made my deployments repeatable, version-controlled, and secure.
Lesson Learned:
I gained a massive appreciation for DevOps. I learned that your infrastructure is part of your application. A poorly configured IAM role is as much a 'bug' as a type error in TypeScript. This experience gave me true end-to-end ownership of an application's lifecycle.
7. Outcomes & Next Steps
Outcomes
This project was a deep-dive into end-to-end system ownership. The 'v1' served as the foundation for the most valuable outcome: the architectural design of a 'v2' production-grade system.
v1 (Technical Achievement): Successfully designed, built, and deployed a full-stack, cloud-native v1 application, achieving a 99 Lighthouse Performance score
v2 (Architectural Outcome): The primary outcome was the in-depth architectural analysis (documented in Section 3), resulting in a complete, production-grade v2 design that solves for scalability, resilience, and performance.
(Personal Outcome): I gained hands-on experience in the entire application lifecycle, from ideation and v1 deployment to identifying critical bottlenecks and designing the v2 enterprise-grade solution.
Next Steps
Implement the Full v2 Architecture: The immediate next step is to execute the v2 plan: Refactor the 'monolithic' Lambda into a true microservice architecture using API Gateway. Implement the asynchronous, SQS-driven image processing pipeline. Integrate the ElastiCache (Redis) layer to provide a sub-10ms cache for all database reads.
Enhance CI/CD & Test Coverage: For v1, I established a CI pipeline using GitHub Actions to automatically run npm run build and npm run typecheck on every push, ensuring the project was always deployable and type-safe. The clear next step is to build out a comprehensive unit and integration test suite with Jest and React Testing Library and add this test stage to the CI pipeline.
Apply Lessons to My Next Project: This is the most important step. I will carry the 'scalability-first' lessons from this project's v2 design directly into my next 'hero' project: an AI-powered recipe generator.